CSCI152 PO-01 Neural Networks
Spring 2022
Tuesday and Thursday
9:35 to 10:50 AM Pacific Time
EDMS Room 229 (Edmunds)
Instructors
Professor Anthony Clark
Research Website
Philosophy
I’d like to give a few brief thoughts on my philosophy and the common traits I’ve seen in successful students.
Philosophy
- I above all aim to be thoughtful.
- I’ve built this class knowing that failure is an important step in learning.
- I want you to realize that you belong here.
- I want to teach you about best learning practices.
- I want you all to work together and get comfortable with your peers.
- I want to acknowledge that diversity, equity, and inclusion are important.
- I love students attending office hours (most faculty do). I teach because I like talking about this stuff–plus it helps me fix my course when you tell me what you don’t understand.
Traits of Success
- Getting started early.
- Sticking to a schedule.
- Self-reflecting on your learning habits.
- Asking questions (even if you think it is simple or dumb).
- Working well with peers.
See my advising page for additional information on CS and being a student at Pomona College.
Teaching Assistants



TAs have the following duties:
- Holding mentoring/help sessions. Similar to office hours, you will have a regular set of times in which you can meet with TAs in-person or over Zoom Slack (depending on your and the TAs preference).
- Grading assignments and providing feedback.
- Creating questions for assignments and checkpoints.
Office and Mentor Hours
Zoom links are pinned in the course Slack Channel.
- Monday
- Prof Clark from 9 to 10 Pacific Time (zoom link on Slack)
- Tony from 3 to 4 Pacific Time (zoom link on Slack)
- Tuesday
- Millie from 3 to 4 PM Pacific Time (zoom link on Slack)
- Wednesday
- Prof Clark from 9 to 10 Pacific Time (zoom link on Slack)
- Prof Clark from 1:30 to 3:30 Pacific Time (zoom link on slack)
- Tony from 3 to 4 Pacific Time (zoom link on Slack)
- Kevin from 5:30 to 6:30 PM Pacific Time (zoom link on Slack)
- Thursday
- Millie from 3 to 4 PM Pacific Time (zoom link on Slack)
- Friday
- Kevin from 5:30 to 6:30 PM Pacific Time (zoom link on Slack)
You can also contact me on Slack to setup additional office hours.
I highly recommend showing up to mentor sessions with the intent that you’ll work on your homework and then ask the occasional question as it pops up.
Objectives
Catalog Description: An introduction to the theory and practical applications of neural networks. This course will cover simple perceptrons through modern convolutional and recurrent neural networks. Topics include gathering and processing data, optimization algorithms, and hyperparameter tuning. Application domains include computer vision, natural language processing, recommender systems, and content generation. Ethical implications of design decisions will also be considered throughout the course.
Prerequisites: Data Structures and Calculus
Learning Objectives: Upon completion of this course, students will be able to:
- Explain ethical considerations of NN applications.
- Explain recent advances in neural networks (i.e., deep learning).
- Explain how NNs compare to other machine learning techniques.
- List and understand the major application domains of NNs.
- Understand and code foundational NN techniques.
- Create, clean, and examine datasets.
- Understand the hyperparameters and dynamics (e.g., bias and variance) of training an NN model.
- Use an NN framework and deploy build a model for a real-world application.
Resources
We will not have a book for this class. But our course structure if fairly close to the fastai book.
This document from fall 2020 is a nice starting point for help. It includes resources for:
- Academics help (writing, quantitative skills, etc.)
- Mental health help
- Technology help (request a laptop, microphone, and/or pre-paid WiFi hotspot) (do you experience slow Internet speeds?)
- Financial help
- Advice from peers (Sage Fellows)
I’d like to recommend listening to the Happiness Lab.
Please let me know if you have any other concerns.
Some helpful links to courses, tutorials, books, etc.
Courses
- fastai (website)
- Deep Learning Specialization (Coursera MOOC)
- Deep Learning (Stanford CS230 course)
- Convolutional Neural Networks for Visual Recognition (Stanford CS231n course)
- Introduction to Deep Learning (MIT 6.S191 course)
- MIT Deep Learning and Artificial Intelligence Lectures (MIT course)
- Deep Reinforcement Learning (Berkeley CS 285 course)
- Deep Reinforcement Learning (free online course)
- Deep Learning Systems
Books
- Deep Learning (free book)
- Dive into Deep Learning (UC Berkeley book)
- First steps towards Deep Learning with PyTorch (free book)
- Neural Networks and Deep Learning (free book)
- Deep Learning With PyTorch (pdf)
- Annotated Algorithms in Python (free book)
- Learn Python the Right way (free book)
- The Linux Command Line by William Shotts
Math
- The Matrix Calculus You Need For Deep Learning (website)
- The Mechanics of Machine Learning (free book)
- Mathematics for Machine Learning (free book)
- Seeing Theory: A Visual Introduction To Probability And Statistics (free book)
Extras
- Cheatsheet (website)
- TensorFlow 2.0 Complete Course - Python Neural Networks for Beginners Tutorial (YouTube)
- Neural Networks (3blue1brown YouTube)
- Machine Learning From Scratch (website)
- A visual introduction to machine learning (website)
Python
- List of free free Python books
- Python Programming Tutorials
- Learn Python - Full Course for Beginners (YouTube)
- Python In 1 Minute (YouTube)
- Automate the Boring Stuff With Python (book)
- Introduction to Python Programming (free course)
- A Whirlwind Tour of Python (Jupyter Notebooks)
- Python for Everybody Specialization (free course)
- Introduction to Computer Science and Programming Using Python (MIT course)
Ethics
- Awful AI
- Learning from the past to create Responsible AI
- Practical Data Ethics
- Fair ML Book
- Machine Ethics Podcast
- ACM Code of Ethics and Professional Conduct
- IEEE Code of Ethics
- Code of Conduct for Professional Data Scientists
Libraries/Frameworks/Tools
- Mlxtend (machine learning extensions)
- Streamlit (Turn data scripts into sharable web apps in minutes)
- Deepnote (The notebook you’ll love to use)
Logistics
These plans are subject to change based on our experiences and your feedback.
For the most part, we will plan on meeting in person, but I have included plans for remote and asynchronous courses below since it may very well come up.
Meeting Periods
Class periods will include a mix of lecture, live coding, and working on group projects. In general, you can expect the following format:
- Prepare for lecture by reading or watching provided materials.
- Complete a pre-lecture survey at least 24 hours prior to lecture.
- Attend lecture where we discuss points of confusion and work through problems.
Zoom Etiquette
You are not expected to have your video on, but it would be nice to turn it on during group discussions in breakout rooms. Also, please set your display name to your preferred name (and include your pronouns if you’d like; for example, “Prof. Clark he/him/his).
During Zoom lectures, I will provide a link to a google sheet that we can use for anonymous discussions.
After lectures, I’d like to leave the zoom room open for an additional 15 minutes for all of you. So, I’ll likely choose willing people to make the host once I leave.
Communication with Slack
Please use Slack (not email) for all communication. If you email me questions, I will likely ask you to make a comment on Slack. This has several benefits:
- You are more likely to get a quick response from me, your fellow students, or your TAs.
- We can easily keep track of our discussion for everyone to see.
- I do not have to repeat answers.
- I can endorse student answers, which is helpful to both the asker and the answerer.
Slack has text, video, and audio options that the TAs and I will use (along with Zoom) to hold office hours and mentoring sessions. I will also use Slack to solicit anonymous feedback on how the course is going. You can create group messages that include you, other classmates, the TAs, and me if you want to discuss a question asynchronously.
Useful Slack commands:
/giphy [search term]- example:
/giphy computers
- example:
/poll <question> <options...> [anonymous] [limit 1]- example:
/poll "How are you?" "Good" "OK" "Bad" anonymous
- example:
/dm @user <msg>- example:
/dm @pomcol What up
- example:
/remind [@someone | #channel] [what] [when]- example:
/remind #cs152sp22 Project "Sep 9"
- example:
/shrug <msg>- example:
/shrug No idea...
- example:
/anon #channel <msg>- example:
/anon #cs152sp22 AHHHHHH...
- example:
/box/collapse/expand
Working Together
I recommend using Slack (text, audio, or video) for communication, and using the Visual Studio Code Live Share Extension for pair programming. We will spend some time in class getting this setup, but these instructions will also be of use.
Feedback
If you have any question for me, I would love for you to ask them on Slack. I will enable a bot that will allow you to make comments anonymously. The CS department also has an anonymous feedback form if you would like to provide feedback outside of class channels.
Grading
Grading for this course is fairly straightforward.
-
You’ll receive an “A” if you
- pass 11 out of 12 assignments,
- pass your project peer evaluation, and
- pass all A-level project milestones (see below).
-
You’ll receive a “B” if you
- pass 9 out of 12 assignments,
- pass your project peer evaluation, and
- pass all B-level project milestones (see below).
-
You’ll receive a “C” if you
- pass all 12 assignments (you can skip working on the project).
Grades of “D” and “F” are reserved for situations in which a student does not meet the criteria above. Mostly it will be for students that work on a successful project, but do not contribute to the project as indicated by peer evaluations. Notice that you can get a “C” in the course by completing the assignments and skipping out on the project. I’ve not had anyone do this before, but the option is there for those that want to spend less time on this course and more time on other activities (courses, life, sports, etc.).
Feedback Surveys
In the Pre-Class column of the schedule you will find links to blog posts, research articles, YouTube videos, videos I create, etc. I expect you to read/watch these materials before class, and I will ask you to complete weekly feedback surveys on gradescope. These surveys are completely optional, but I encourage you to participate if you want to get the most out of the course.
These will make lectures more concrete and provide you with a means of giving me feedback (for example, on a topic that I didn’t cover well).
Assignments
You will submit assignments to gradescope. You may work on assignments individually or with a partner of your choice. If you’d like to be assigned a partner, please send me a message on Slack and I will randomly assign partners when I have a pool of students.
Assignments will not be graded per se; instead, you will meet with a TA and walk them through your answers and code. They will then mark your assignment as “passed” or “needs revisions”. You should not meet with a TA until you have completed your assignment. Of course, you can still visit them during mentor sessions to ask for help.
If you do not pass an assignment on the first meeting, then you will need to work on your answers, resubmit, and then schedule a new time to meet with a TA. As a rule-of-thumb, you can think of a “pass” as at least a 90% on the assignment.
Project
Everyone is expected to complete a course project related to neural networks (though you can still pass the course without the project). All projects reports will be hosted as websites. Project grading will rely heavily on self-assessments and peer evaluations.
Project Milestones
Course projects have the following milestones (see the schedule for exact deadlines).
- Individual Proposals (due week 3)
- Introduction Outline (due week 4)
- Related Works Search (due week 5)
- Project Update 1 (due week 6)
- Self-Assessment and Peer Evaluations 1 (due week 6)
- Introduction and Related Works Draft (due week 7)
- Project Update 2 (due week 8)
- Methods Outline (due week 9)
- Self-Assessment and Peer Evaluations 2 (due week 10)
- Discussion Outline (due week 11)
- Complete Rough Draft (due week 14)
- Final Self-Assessment and Peer Evaluations (due Monday finals week)
- Complete Project and Revisions (due Wednesday finals week)
Why Develop a Project Like This?
I want you to work on your project this way because it makes it easier for:
- you all to keep momentum throughout the semester,
- everyone to see each others work,
- me to see what you’ve changed after revisions (by looking at your commit history and diffs), and
- partners to work together on a single code-base.
Project Levels
A-level project milestones
All thirteen project milestones must be marked as “pass.”
B-level project milestones
All project milestones 1 through 11 (the Complete Rough Draft due week 14) must be marked as “pass.”
C-level project milestones
The following project milestones must be marked as “pass”:
- Individual Proposals (due week 3)
- Introduction Outline (due week 4)
- Literature Review (due week 5)
- Project Update 1 (due week 6)
- Introduction and Related Works Draft (due week 7)
- Project Update 2 (due week 8)
- Methods Outline (due week 9)
- Discussion Outline (due week 11)
- All three Peer Evaluations (due weeks 6, 10, and finals)
Peer Evaluations
Peer evaluations are used as a way to ensure that all group members are contributing. If group members disagree in the evaluations I will ask for more information, and it is possible that I will make appropriate grade adjustments based on this feedback.
Policies
Accommodations
If you have a disability (for example, mental health, learning, chronic health, physical, hearing, vision, neurological, etc.) and expect barriers related to this course, it is important to request accommodations and establish a plan. I am happy to help you work through the process, and I encourage you to contact the Student Disability Resource Center (SDRC) as soon as possible.
I also encourage you to reach out to the SDRC if you are at all interested in having a conversation. (Upwards of 20% of students have reported a disability.)
Academic Honesty and Collaboration
I encourage you to study and work on assignments with your peers (unless otherwise specified). If you are ever unsure about what constitutes acceptable collaboration, please ask!
For more information, see the Computer Science Department and the Pomona College policies.
I take violations of academic honesty seriously. I believe it is important to report all instances, as any leniency can reinforce (and even teach) the wrong mindset (“I can get away with cheating at least once in each class.”).
Academic Advisory Notice
I will do my best to update you if I think you are not performing at your best or if you are not on pace to pass the class. I will first reach out to you and then use the system built-in to my.pomona.edu that will notify your advisor so you are encouraged to work with a mentor or advisor on a plan.
Attendance
I expect you to attend every class, but I will not penalize you for missing class. Know that there is a strong correlation between attendance and grades, and you will almost certainly be indirectly penalized.
You are responsible for any discussions, announcements, or handouts that you miss, so please reach out to me. If you need to leave class early for any reason, please let me know before class begins so that I am not concerned when you leave.
Late Submissions
Late assignments will not be accepted. However, if you plan ahead you can ask for an extension prior to the assignment deadline (at least four days).
Unless requested ahead of time, some assessments (e.g., exams) cannot be completed after the class period in which they are scheduled.
Covid Safety Awareness
During the past academic year, we built community remotely, and this year we will build on the pedagogical improvements we acquired last year. For example, we might meet on zoom from time to time, or hold discussions online.
Our health, both mental and physical, is paramount. We must consider the health of others inside and outside the classroom. All Claremont Colleges students have signed agreements regulating on-campus behavior during the pandemic; in the classroom, we will uphold these agreements. We need to take care of each other for this course to be successful. I ask you therefore to adhere to the following principles:
- there is a mask mandate for all indoor spaces on campus. You must wear a mask for the entire class; eating and drinking are not permitted. Your mask must cover your mouth and nose. The college has zero-tolerance for violations of this policy, and our shared commitment to the health and safety of our community members means if you come to class unmasked you will have to leave class for the day.
- Class attendance is required, but if you need to miss class for health reasons, concerning symptoms, suspected Covid exposure, unexpected dependent care, technology issues, or other emergency reasons I will work with you. Let me underscore this: please make your decisions always based on health, safety, and wellness—yours and others—and I will work with you at the other end. Take any potential symptoms seriously; we’re counting on each other.
- When not in class, avoid closed public spaces, and if you can’t avoid them: wear your mask properly, wash your hands, and maintain social distance.
- If you, or a family member, are experiencing hardship because of the pandemic, talk to me or to someone in the Dean of Students office. You are not alone during this time.
The pandemic is fast-moving, and we might have to adjust these principles as the semester evolves. I am always happy to receive your feedback to make this course work.
Let’s care for each other, show empathy, and be supportive. While there will likely be some community transmission and breakthrough infections, together, we can minimize their effect on our community and on your learning.
Calendar
Schedule
If the schedule below doesn’t look up-to-date, you might need to reload the page while overriding cache.
Here are all resources from the previous time this course was taught
The check-boxes are for your own use so that you can easily come back to this page and see where you left off (I can’t see what you do on this page). I’m using localstorage to get this working, so no guarantees it will work on your device.
| Date | Pre-Class | In-Class | Assignment |
|---|---|---|---|
| Tue Jan 18 |
| ||
| Thu Jan 20 | |||
| Tue Jan 25 |
|
| |
| Wed Jan 26 |
| ||
| Thu Jan 27 | |||
| Tue Feb 01 | |||
| Wed Feb 02 |
| ||
| Thu Feb 03 |
| ||
| Tue Feb 08 |
| ||
| Thu Feb 10 | |||
| Tue Feb 15 |
| ||
| Wed Feb 16 |
| ||
| Thu Feb 17 | |||
| Tue Feb 22 |
| ||
| Wed Feb 23 |
| ||
| Thu Feb 24 | |||
| Tue Mar 01 |
| ||
| Wed Mar 02 |
| ||
| Thu Mar 03 | |||
| Tue Mar 08 |
| ||
| Wed Mar 09 |
| ||
| Thu Mar 10 |
| ||
| Tue Mar 15 | Spring break -- No Class | ||
| Thu Mar 17 | Spring break -- No Class | ||
| Tue Mar 22 |
| ||
| Wed Mar 23 |
| ||
| Thu Mar 24 | |||
| Tue Mar 29 |
| ||
| Wed Mar 30 |
| ||
| Thu Mar 31 | |||
| Tue Apr 05 |
| ||
| Wed Apr 06 |
| ||
| Thu Apr 07 | |||
| Tue Apr 12 |
| ||
| Wed Apr 13 |
| ||
| Thu Apr 14 | |||
| Tue Apr 19 |
| ||
| Wed Apr 20 |
| ||
| Thu Apr 21 | |||
| Tue Apr 26 |
| ||
| Wed Apr 27 |
| ||
| Thu Apr 28 |
| ||
| Tue May 03 |
| ||
| Thu May 05 |
| ||
| Mon May 09 | |||
| Wed May 11 |
|
Course Units
Unit 1: Introduction, Demos, and Ethics
We will start by digging into demos created using PyTorch, Hugging Face, and Streamlit. I want to quickly show you some application areas and give you an idea of the different possibilities for projects.
We will discuss applications of deep learning and ethical implications.
Unit 2: Neural Networks from First Principles
Next we will learn how to build neural networks from scratch by deriving the backpropagation algorithm by hand and using Python for implementations.
Unit 3: Advanced Topics
The next major chunk of the class will be devoted to higher-level concepts and state-of-the-art techniques.
Unit 4: Project Demonstrations
We will end the semester with project presentations/demonstrations.
Terminology
Machine Learning
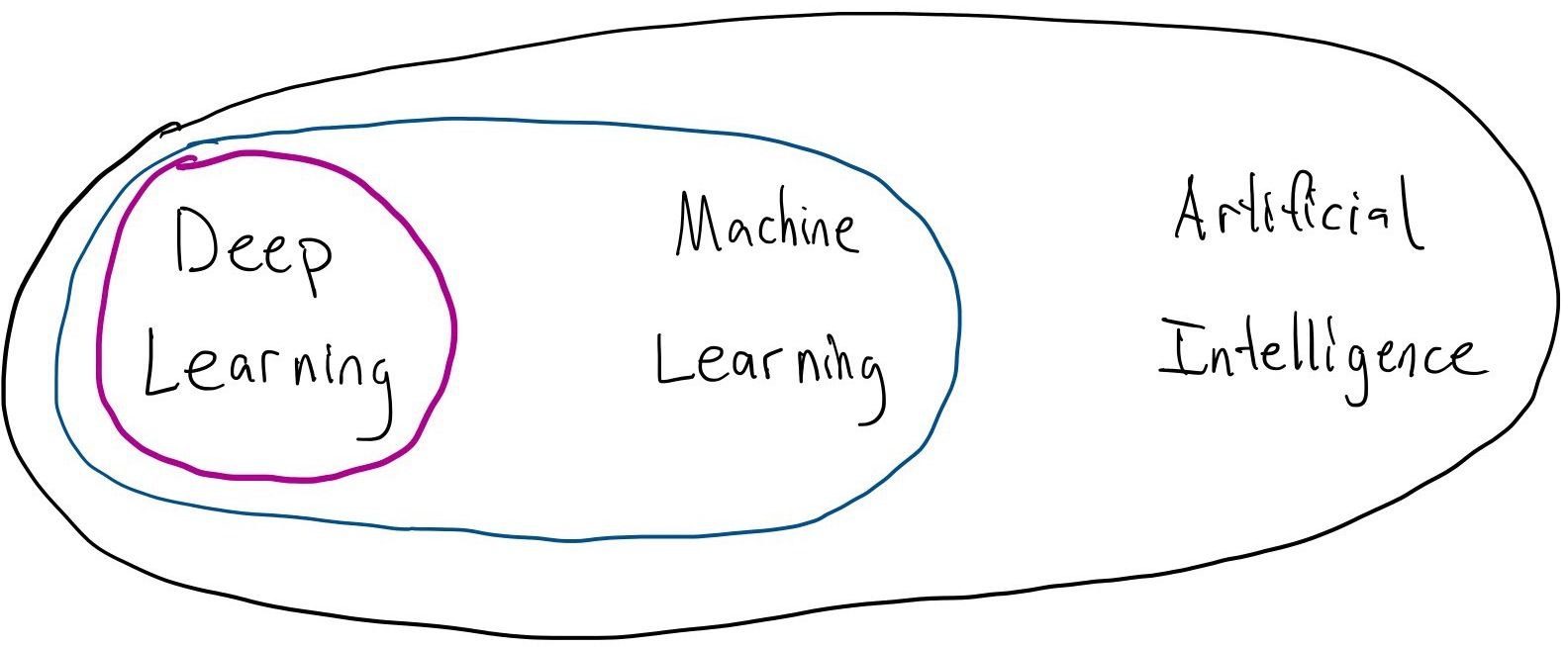
Artificial Intelligence (AI): computer systems that are capable of completing tasks that typically require a human. This is a moving bar–as something becomes easier for a computer, we tend to stop considering it as AI (how long until deep learning is not AI?).
Machine Learning (ML): learn a predictive model from data (e.g., deep learning and random forests). ML is related to data mining and pattern recognition.
Deep Learning (DL): learn a neural network model with two or more hidden layers.
Supervised Learning: learn a mapping from input features to output values using labeled examples (e.g., image classification).
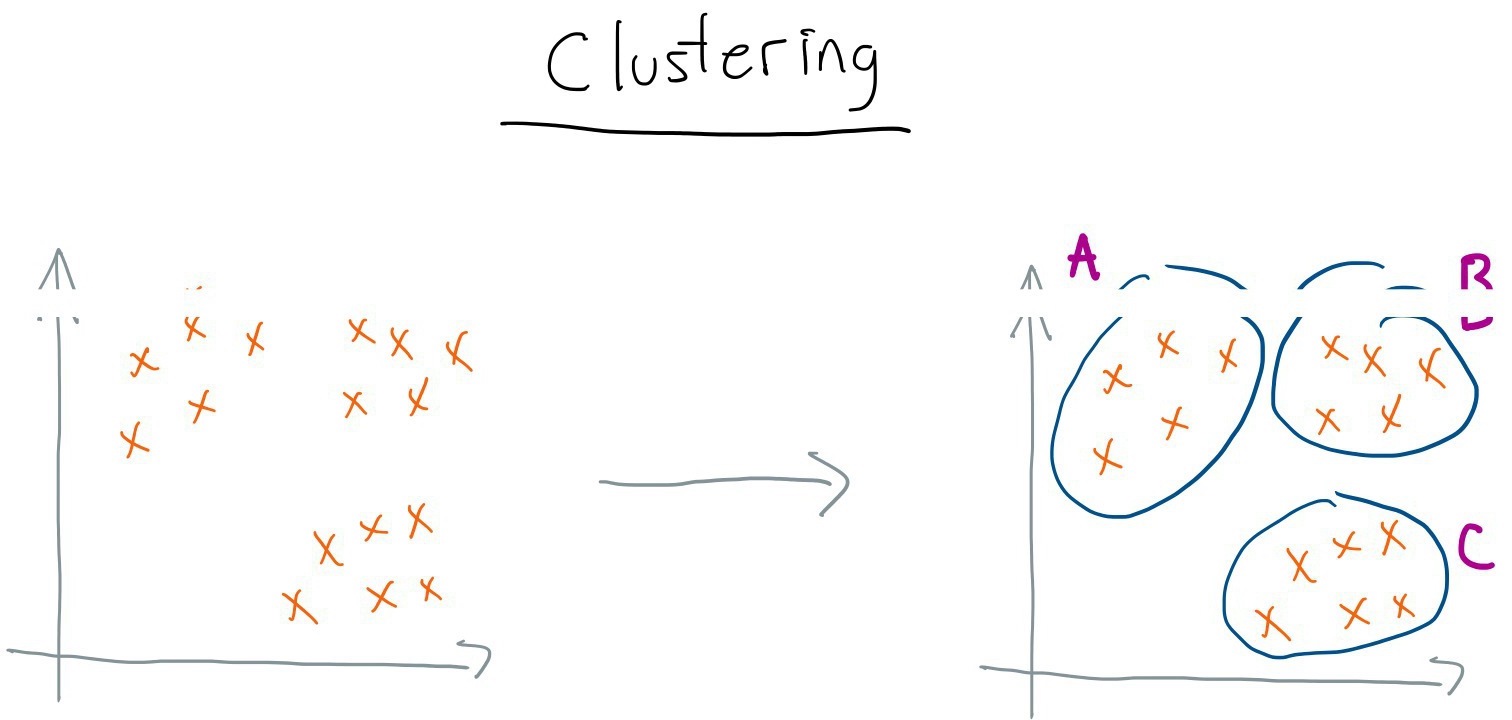
Unsupervised Learning: extract relationships among data examples (e.g., clustering).
Reinforcement Learning (RL): learn a model that maximizes rewards provided by the environment (or minimize penalties).
Hybrid Learning: combine methods from supervised, unsupervised, and reinforcement learning (e.g., semi-supervised learning).
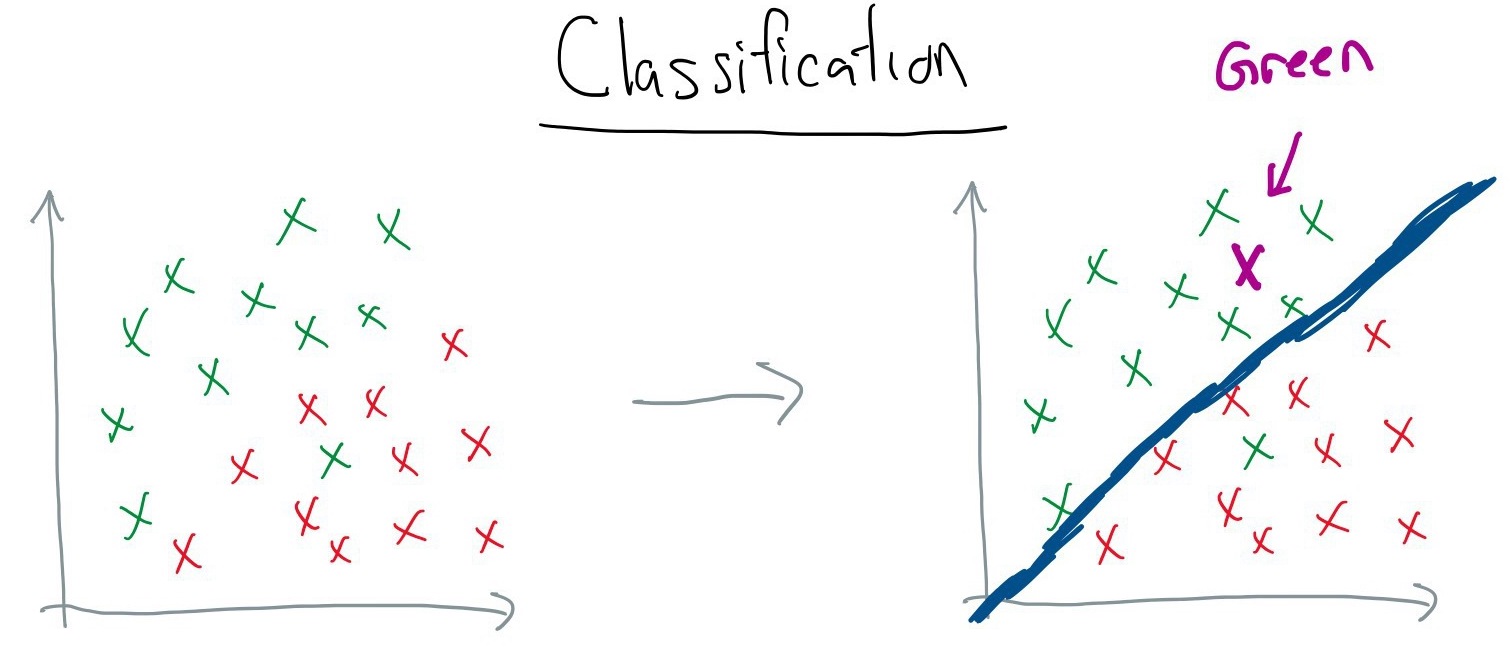
Classification: given a set of input features, produce a discrete output value (e.g., predict whether a written review is negative, neutral, or positive).
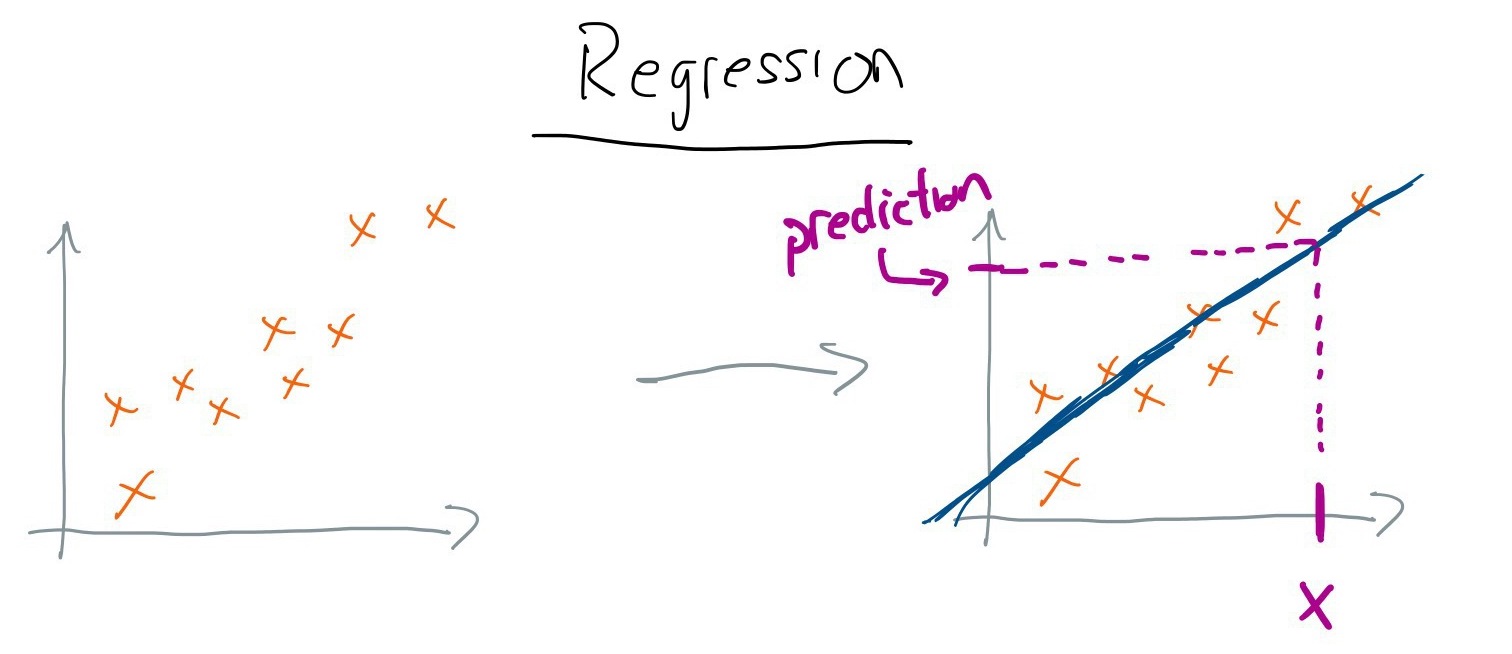
Regression: given a set of input features, produce a continuous output value (e.g., predict the price of a house from the square footage, location, etc.).
Clustering: a grouping of input examples such that those that are most similar are in the same group.
Model: (predictor, prediction function, hypothesis, classifier) a model along with its parameters.
Example: (instance, sample, observation, training pair) an input training/validation/testing input (along with its label in the case of supervised learning).
Input: (features, feature vector, attributes, covariates, independent variables) values used to make predictions.
Channel: subset of an input–typically refers to the red, green, or blue values of an image.
Output: (label, dependent variable, class, prediction) a prediction provided by the model.
Linear Separability: two sets of inputs can be divided a hyperplane (a line in the case of two dimensions). This is the easiest case for learning a binary classification.
Neural Network Terms

Neural Network (NN): (multi-layer perceptron (MLP), artificial NN (ANN)) a machine learning model (very loosely) based on biological nervous systems.
Perceptron: a single layer, binary classification NN (only capable of learning linearly separable patterns).
Neuron: (node) a single unit of computation in a NN. A neuron typically refers to a linear (affine) computation followed by a nonlinear activation.
Activation: (activation function, squashing function, nonlinearity) a neuron function that provides a nonlinear transformation (see this Stack Exchange Post for some examples and equations).
Parameter: (weights and biases, beta, etc.) any model values that are learned during training.
Layer: many NNs are simply a sequence of layers, where each layer contains some number of neurons.
Input Layer: the input features of a NN (the first “layer”). These can be the raw values or scaled values–we typically normalize inputs or scale them to either [0, 1] or [-1, 1].
Hidden Layer: a NN layer for which we do not directly observe the values during inference (all layers that are not an input or output layer).
Output Layer: the final layer of a NN. The output of this layer is (are) the prediction(s).
Architecture: a specific instance of a NN, where the types of neurons and connectivity of those neurons are specified (e.g., VGG16, ResNet34, etc.). The architecture sometimes includes optimization techniques such as batch normalization.
Forward Propagation: the process of computing the output from the input.
Training: the process of learning model parameters.
Inference: (deployment, application) the process of using a trained model.
Dataset: (training, validation/development, testing) a set of data used for training a model. Typically a dataset is split into a set used for training (the training set), a set for computing metrics (the validation/development set), and a set for evaluation (the testing set).
Convolutional Neural Network (CNN): a NN using convolutional filters. These are best suited for problems where the input features have geometric properties–mainly images (see 3D Visualization of a Convolutional Neural Network).
Filter: a convolution filter is a matrix that can be used to detect features in an image; they will normally produce a two-dimensional output (see Image Kernels Explained Visually, Convolution Visualizer, and Receptive Field Calculator). Filters will typically have a kernel size, padding size, dilation amount, and stride.
Pooling: (average-pooling, max-pooling, pooling layer) a pooling layer is typically used to reduce the size of a filter output.
Autoencoder: a common type of NN used to learn new or compressed representations.
Recurrent Neural Network (RNN): A NN where neurons can maintain an internal state or backward connections and exhibit with temporal dynamics. One type of RNN is a recursive neural network.
Long Short-Term Memory (LSTM): a common type of RNN developed in part to deal with the vanishing gradient problem (see Understanding LSTM Networks and Recurrent Neural Networks (RNN) and Long Short-Term Memory (LSTM) (YouTube)).
Learning Terms
Loss: (loss function) a function that we minimize during learning. We take the gradient of loss with respect to each parameter and then move down the slope. Loss is frequently defined as the error for a single example in supervised learning.
Cost: (cost function) similar to loss, this is a function that we try to minimize. Cost is frequently defined as the sum of loss for all examples.
Generalization: how well a model extrapolates to unseen data.
Overfitting: how much the model has memorized characteristics of the training input (instead of generalizing).
Regularization: a set of methods meant to prevent overfitting. Regularization reduces overfitting by shrinking parameter values (larger parameters typically means more overfitting).
Bias: when a model has larger-than-expected training and validation loss.
Variance: when model has a much larger validation error compared to the training error (also an indication of overfitting).
Uncertainty: some models can estimate a confidence in a given prediction.
Embedding: a vector representation of a discrete variable (e.g., a method for representing an English language word as an input feature).
Activation Terms
Affine: (affine layer, affine transformation) the combination of a linear transformation and a translation (this results in a linear transformation).
Nonlinear: a function for which the change in the output is not proportional to the change in the input.
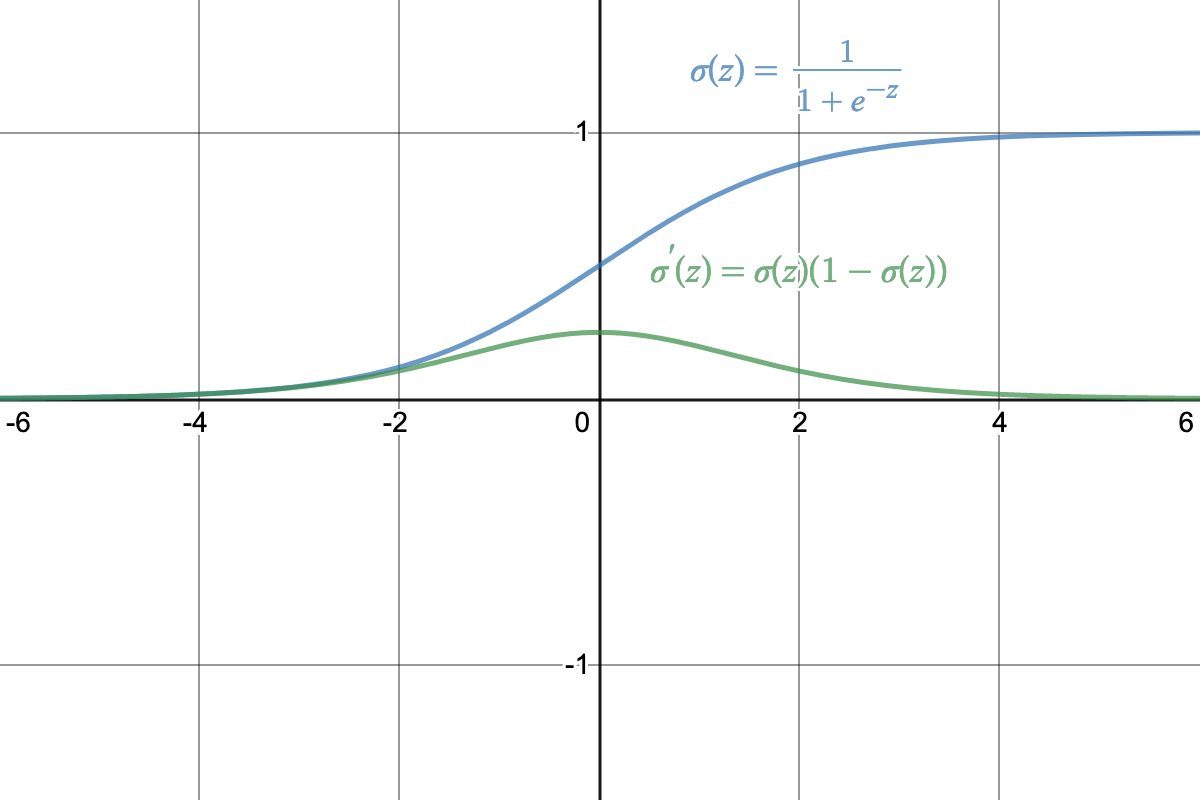
Sigmoid: (sigmoid curve, logistic curve/function) a common activation function that is mostly used in the output layer of a binary classifier. Gradient is small whenever the input value is too far from 0.
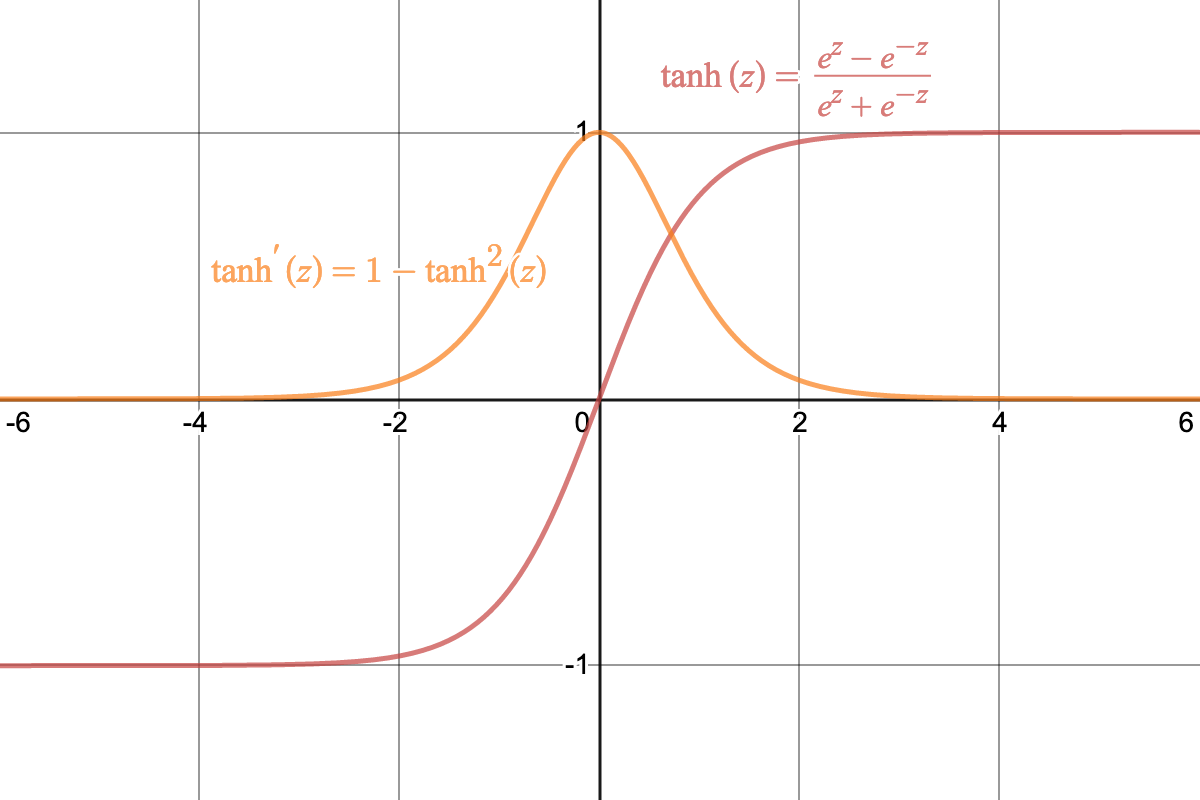
Hyperbolic Tangent: (tanh) another (formerly) common activation funtcion (better than sigmoid, but typically worse than ReLu). Gradient is small whenever the input value is too far from zero.
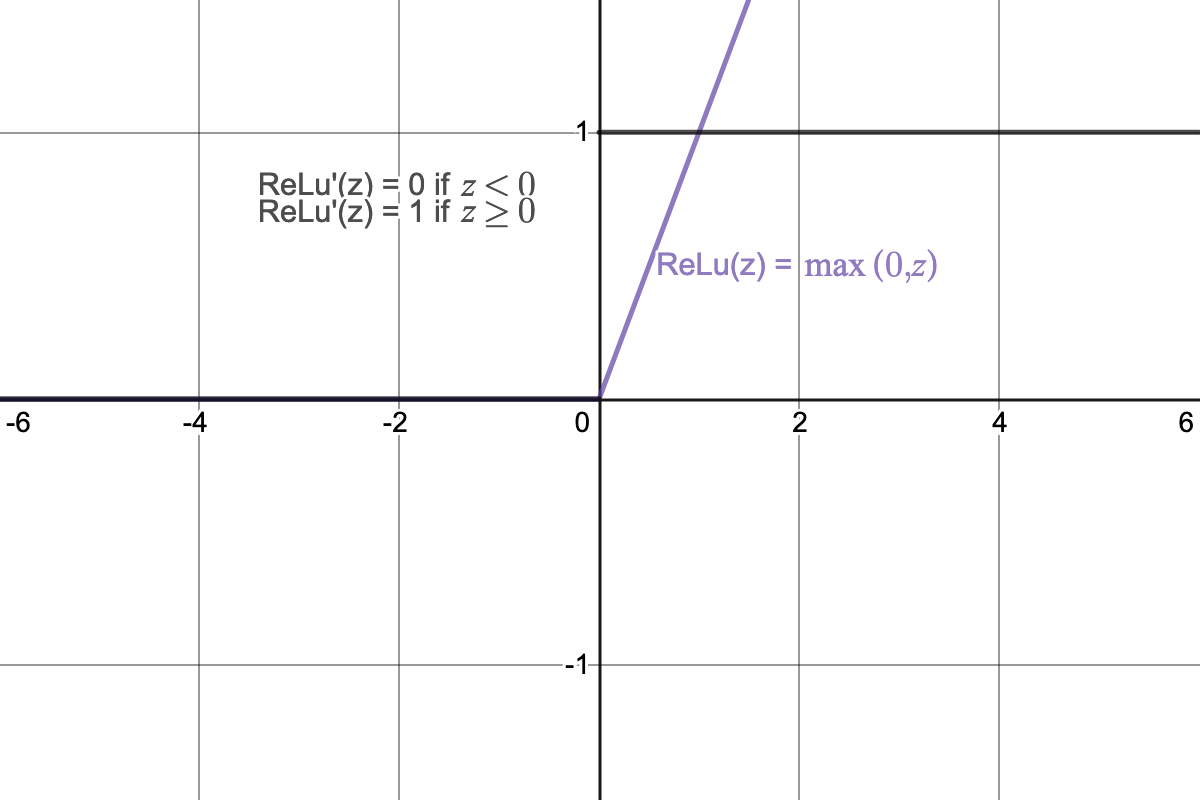
ReLu: (rectified linear unit, rectifier) the most widely used activation function.
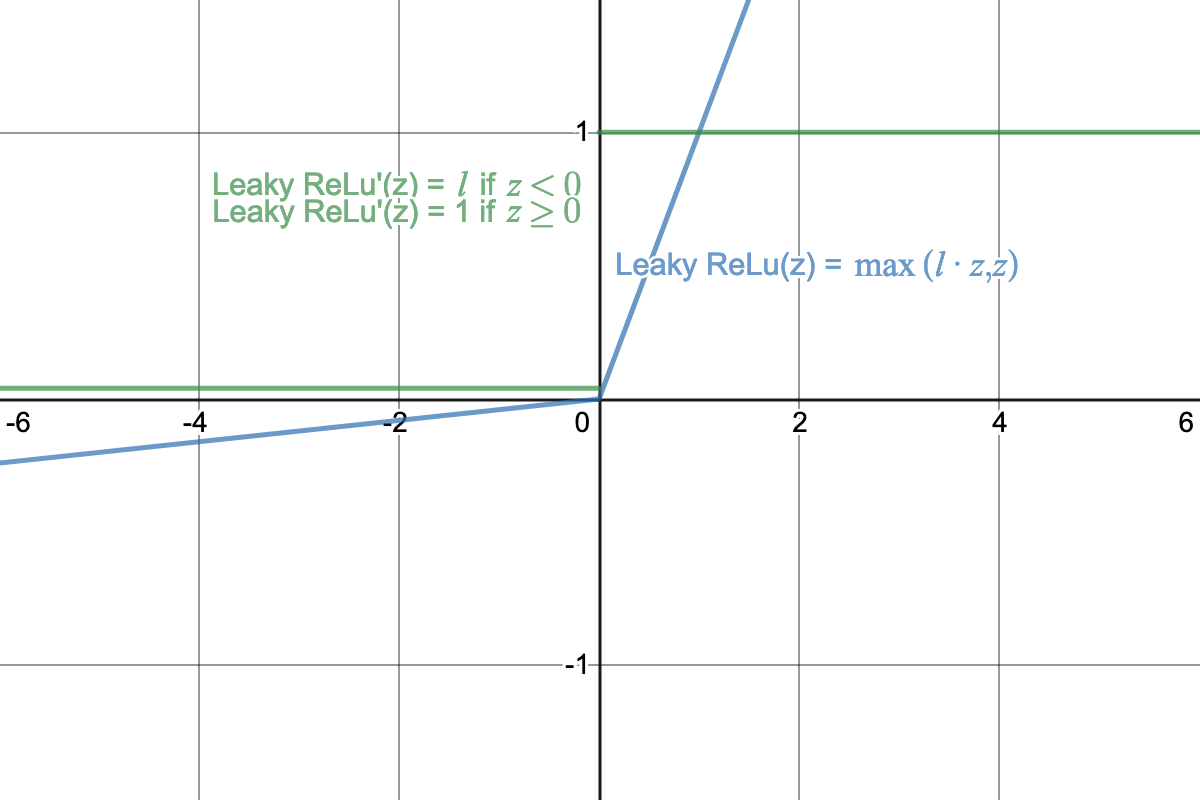
Leaky ReLu: a slightly modified version of ReLu where there is a non-zero derivative when the input is less than zero.
Softmax: (softmax function, softargmax, log loss) is a standard activation function for the last layer of a multi-class NN classifier. It turns the outputs of several nodes into a probability distribution (see The Softmax function and its derivative).

Learning Techniques
Data Augmentation: the process of altering inputs each epoch thereby increasing the effective training set size.
Transfer Learning: use a trained model (or part of it) on an input from a different distribution. Most frequently this also involve fine-tuning.
Fine-tuning: training/learning only a subset of all parameters (usually only those nearest the output layer).
Dropout: a regularization technique in which neurons are randomly zeroed out during training.
Batch Normalization: is a technique that speeds up training by normalizing the values of hidden layers across input batches. Normalizing hidden neuron values will keep derivatives higher on average.
Attention: (attention mechanism, neural attention) is a technique that enables a NN to focus on a subset of the input data (see Attention in Neural Networks and How to Use It).
Optimization
Gradient Descent (GD): (stochastic GD (SGD), mini-batch GD) a first-order optimization algorithm that can be used to learn parameters for a model.
Backpropagation: application of the calculus chain-rule for NNs.
Learning Rate: a hyperparameter that adjusts the training speed (too high will lead to divergence).
Vanishing Gradients: an issue for deeper NNs where gradients saturate (becomes close to zero) and training is effectively halted.
Exploding Gradients: an issue for deeper NNs where gradients accumulate and result in large updates causing gradient descent to diverge.
Batch: a subset of the input dataset used to update the NN parameters (as opposed to using the entire input dataset at once).
Epoch: each time a NN is updated using all inputs (whether all at once or using all batches).
AdaGrad: a variant of SGD with an adaptive learning rate (see Papers with Coe: AdaGrad).
AdaDelta: a variant of SGD/AdaGrad (see Papers With Code: AdaDelta).
Adam: a variant of SGD with momentum and scaling (see Papers With Code: Adam).
RMSProp: a variant of SGD with an adaptive learning rate (see Papers With Code: RMSProp).
Momentum: an SGD add-on that speeds up training when derivatives stay the same sign each update.
Automatic Differentiation (AD): a technique to numerically/automatically evaluate the derivative of a function.
Cross-Entropy Loss: (negative log likelihood (NLL), logistic loss) a loss function commonly used for classification.
Backpropagation Through Time: (BPTT) a gradient-based optimization technique for recurrent neural networks.