3D Graphics
Key Points
- Refresher
[ ]What are the main stages of the 3D graphics pipeline?[ ]How does an application send commands to the GPU to render a scene?[ ]What is a buffer (in the context of Vulkan) and what are some things buffers are used for?[ ]How do we change vertices at runtime?[ ]What are normalized device coordinates?[ ]What is a Vulkan graphics pipeline for?[ ]What is a descriptor set?
- Billboarded Sprites
[ ]How does indexed drawing differ from direct drawing?[ ]If we want to draw a bunch of moving rectangles, how do we update their positions on the GPU every frame?[ ]What challenges do we face if the number of moving rectangles can change dynamically?[ ]What are uniforms and how do they relate to shaders?[ ]How can we work in coordinate spaces besides normalized device coordinates?[ ]What is sprite batching and why is it important?
Recommended Readings
Starting to Draw Stuff in 3D
So far, we've been using a 3D graphics API really just to get us a swapchain and to draw one big image. This week we'll finally draw more than one triangle at a time. Before, we needed to come up with three vertices and a texture—and to do that we needed 800 lines of Vulkan junk! Luckily, we've paid most of our complexity cost already, so we can change over to drawing a bunch of things pretty easily.
Sprite Data
First, let's delete the FramebufferScheme and FramebufferData types and any values of those types.
We'll replace them with sprite stuff.
Let's also change the engine data: for now we'll draw from just one spritesheet, and we'll store just the data we need to draw sprites from that spritesheet.
That means a texture (both on CPU and GPU) for the spritesheet, and for each sprite its location, size, and the top left corner of the animation cel it's supposed to use (we'll assume here that the size of the sprite is 1:1 with the size of the animation cels).
pub struct Engine { texture: (Rc<Image>, Arc<vulkano::image::immutable::ImmutableImage>), // this tuple has: positions, sizes, top left corner of spritesheet cel sprite_data: (Vec<Vec2>, Vec<Vec2>, Vec<Vec2>), // Then the engine stuff event_loop: Option<EventLoop<()>>, vulkan_config: VulkanConfig, vulkan_state: VulkanState, input: Input, world_size: Vec2, }
To add a new sprite we'd want to do something like this:
pub fn add_sprite(&mut self, pos: Vec2, sz: Vec2, cel_pos: Vec2) { let (posns, sizes, cel_posns) = &mut self.sprite_data; assert_eq!(posns.len(), sizes.len()); assert_eq!(posns.len(), cel_posns.len()); posns.push(pos); sizes.push(sz); cel_posns.push(cel_pos) }
This pattern of having parallel vecs is something we'll return to in a few weeks. The alternative would be something like:
struct SpriteData { position:Vec2, size:Vec2, cel_pos:Vec2 } // sprite_data:Vec<SpriteData>
Textures
We'll get into why parallel vecs may be a better choice when we talk about data and performance.
In this version of the engine, we support just one texture; but even if we want to expand to many textures, image loading needs to be a little more complex to upload the texture to the GPU:
// From this... let img = Image::from_file(tex); // To this! let (vulk_img, fut) = vulkano::image::immutable::ImmutableImage::from_iter( img.as_slice().iter().copied(), vulkano::image::ImageDimensions::Dim2d { width: img.sz.x, height: img.sz.y, array_layers: 1, }, vulkano::image::MipmapsCount::One, vulkano::format::Format::R8G8B8A8_SRGB, vulkan_config.queue.clone(), ) .unwrap(); // fancy! let old_fut = vulkan_state.previous_frame_end.take(); vulkan_state.previous_frame_end = match old_fut { None => Some(Box::new(fut)), Some(old_fut) => Some(Box::new(old_fut.join(fut))), };
We could have avoided the business with futures by just letting fut drop, but that would cause image loading to hang until the texture is uploaded; better to continue to do useful work!
Rendering
Finally, we need to use our SpriteScheme and SpriteData to actually draw our billboarded sprites in 3D, whatever that means. In render3d:
let mut builder = AutoCommandBufferBuilder::primary( vulkan_config.device.clone(), vulkan_config.queue.family(), CommandBufferUsage::OneTimeSubmit, ) .unwrap(); // New! This replaces "copy the framebuffer to the GPU" vulkan_state.sprite_data.prepare_draw( &vulkan_config.sprite_scheme, vulkan_config.device.clone(), &self.sprite_data, &self.texture, self.world_size, ); builder .begin_render_pass( vulkan_state.framebuffers[image_num].clone(), SubpassContents::Inline, std::iter::once(vulkano::format::ClearValue::Float([0.0; 4])), ) .unwrap() .set_viewport(0, [vulkan_state.viewport.clone()]); // New! This replaces "render the framebuffer in a full-screen triangle" vulkan_state .sprite_data .draw_sprites(&vulkan_config.sprite_scheme, &mut builder); builder.end_render_pass().unwrap();
Billboarded Sprites
The key idea in modern 3D programming is that you're setting up your own little program on the GPU, with its own inputs and outputs. This means that you need to decide on a format for the input (a vertex type, vertex and index buffers, textures and samplers, etc), design pipelines to handle that input, write shaders to process those inputs, and so on. Each renderer (and in fact each kind of thing we want to render) is sui generis, unique unto itself.
Let's design a renderer for billboarded sprites. We know the game data coming in: sprite positions and sizes and animation cels, and a spritesheet texture. We need to create for each such sprite two triangles in a rectangular layout, with UVs that pull from the right part of the spritesheet to map the correct animation frame onto the quadrilateral. If the sprite is at \(x,y\), has size \(w,h\), and top-left spritesheet corner \(u,v\) for a texture which with dimensions \(tw,th\), we can get the four triangle points if we assume the sprite's animation cel in the tilesheet is just as large as the sprite in pixels. We need to divide through by \(tw\) and \(th\) because UV coordinates are normalized.
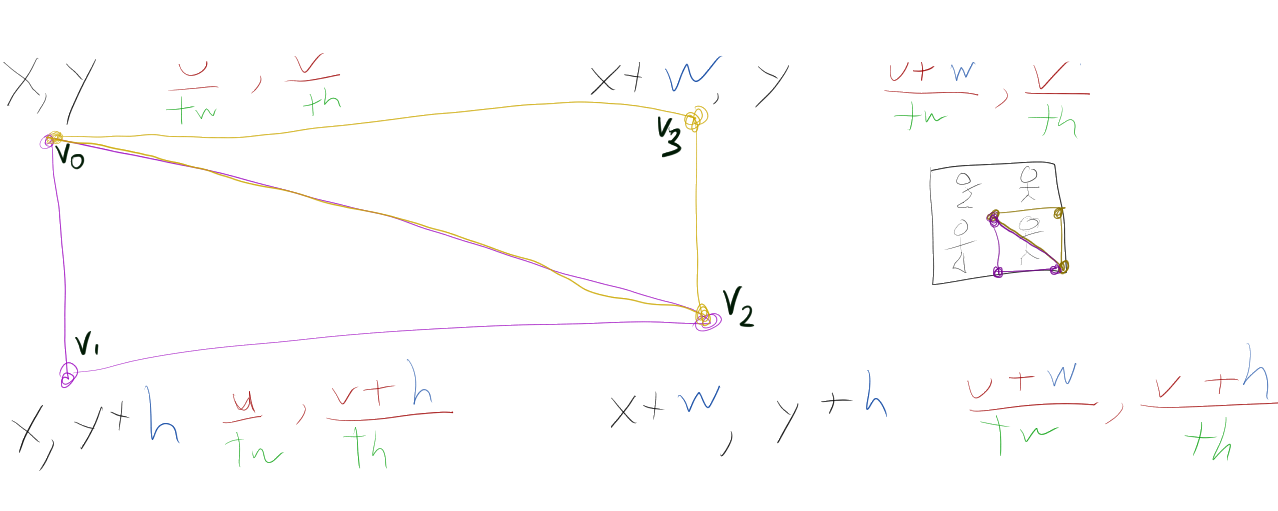
Notice that we have four points (v0 through v3), but we need to make two triangles.
Since each triangle is defined by three vertices, one way to solve this would be to duplicate v0 (as v5)and v2 (as v4) and lay them out like [v0, v1, v2, v4, v3, v5].
But this means we pay the cost of two extra vertices for each sprite, which feels wrong somehow (and costs at least 2*sizeof(Vertex) = 2*sizeof(f32)*4 = 32 bytes, which is not nothing).
Instead, we're going to also introduce indexed drawing.
In indexed drawing, we have one vertex buffer as before, but instead of defining all the triangles it just defines the set of vertices to be used.
We also define an index buffer full of indices into that vertex buffer.
In the example above, if our vertex buffer were [v0, v1, v2, v3], our index buffer would be something like [0, 1, 2, 2, 3, 0].
Indices are tiny compared to vertices (if they're u16 values for instance, an index is only 2 bytes instead of 16 for a Vertex), so even using 6 of them (12 bytes) is cheaper than the three extra vertices we'd need for non-indexed drawing.
In complex 3D models where triangles often share two of their vertices (and each vertex carries much more data), the savings are even more pronounced.
Notably, the shaders and pipeline don't care whether you're using indexed drawing or not; it all happens at the level of draw calls.
We'll update the sampler for this texture so that it doesn't blur anything (this is important to avoid bits of adjacent animation cels leaking into the current cel):
let sampler = Sampler::new( device.clone(), Filter::Nearest, Filter::Nearest, MipmapMode::Nearest, SamplerAddressMode::Repeat, SamplerAddressMode::Repeat, SamplerAddressMode::Repeat, 0.0, 1.0, 0.0, 0.0, ) .unwrap();
We also want new shaders.
Importantly, our vertices as above are in pixel coordinates (or, if you like, world coordinates), not the normalized device coordinates of the framebuffer example.
So we need to give our shader the information it needs to convert world-space vertex coordinates to NDCs: a uniform which is the same across all vertices giving a translation and scale transformation.
Here we'll call it viewproj since it combines a view transformation and projection transformation.
#version 450 // This is new... layout(set=0, binding=0) uniform SpriteData { mat4 viewproj; }; layout(location = 0) in vec2 position; layout(location = 1) in vec2 uv; layout(location = 0) out vec2 out_uv; void main() { // Note this multiply! Matrix-vector multiplication is transformation gl_Position = viewproj*vec4(position, 0.0, 1.0); out_uv = uv; }
We also want to support transparent pixels, and rather than futz around with blending modes it will be simplest for now to discard pixels with low alpha values and just not draw in them:
#version 450 // Note that the set for the texture sampler changed! layout(set = 1, binding = 0) uniform sampler2D tex; layout(location = 0) in vec2 uv; layout(location = 0) out vec4 f_color; void main() { vec4 col = texture(tex, uv); // This is new! discard is a magic word if (col.a < 0.1) { discard; } f_color = col; }
Our SpriteScheme will store much less data than before, since fewer assumptions are being made. Just a sampler (common across all sprites) and a pipeline describing how drawing works.
struct SpriteScheme { pipeline: Arc<vulkano::pipeline::GraphicsPipeline>, sampler: Arc<Sampler>, }
We'll initialize SpriteScheme by setting up these shaders and a pipeline, and create a SpriteData object to manage the part of the rendering state that changes from frame to frame.
One important piece of that state is the new uniform buffer to hold the view-projection matrix, so we'll have a function like this in SpriteScheme:
fn create_sprite_data(&self, device: Arc<Device>) -> SpriteData { // Create uniform storage let uniform = CpuAccessibleBuffer::from_data( device, BufferUsage::uniform_buffer(), false, // Just use an identity matrix [Mat4::from_nonuniform_scale(Vec3::new(1.0_f32, 1.0, 1.0))], ) .unwrap(); // Create a binding to use this storage let mut set_b = PersistentDescriptorSet::start( self.pipeline .layout() .descriptor_set_layouts() .get(0) .unwrap() .clone(), ); // Add the storage to the binding set_b.add_buffer(uniform.clone()).unwrap(); let pds = set_b.build().unwrap(); // Here we go! SpriteData { data: None, uniform_buffer: uniform, uniform_pds: pds, } }
But SpriteData looks totally different from our old FramebufferData.
Besides storing the uniform buffer and descriptor set, we also need it to handle GPU memory holding the sprites to be drawn.
We need to know how many sprites to draw, their vertices, the indices used to draw their vertices, and a descriptor set with their texture and sampler.
For this exposition we'll focus on drawing a bunch of sprites that use a single texture; in a real application you'd want data to be a collection like a Vec or BTreeMap that contains groups (or batches) of sprites sharing the same texture.
struct SpriteData { // TODO: instead of an Option, wrap data in a BTreeMap to support multiple distinct spritesheets // (count of sprites, vertex buffer, index buffer, texture+sampler) data: Option<( usize, Arc<CpuAccessibleBuffer<[Vertex]>>, Arc<CpuAccessibleBuffer<[u16]>>, Arc<vulkano::descriptor_set::PersistentDescriptorSet>, )>, // we'll also use one uniform buffer the whole time. // it will be the screen transform. // we'll assume every vertex is positioned in the same coordinate space. uniform_buffer: Arc<CpuAccessibleBuffer<[Mat4; 1]>>, uniform_pds: Arc<vulkano::descriptor_set::PersistentDescriptorSet>, }
To draw sprites now, we need to do three things:
- Update the uniform buffer with scaling and translation information (the "camera")
- Update
data, copying over changes to sprite data and possibly destroying and recreating the buffers if the number of sprites has changed too much - Bind the pipeline, descriptor sets, and vertex buffers, and then issue draw commands.
(1) and (2) are "prepare" moves—they should happen before we start issuing drawing commands.
We'll start with the uniform buffer.
If we know how big the screen is supposed to be in world coordinates (sz), we can scale the drawing so that the -1..1 interval in the \(x\) dimension maps onto 0..sz.x, and likewise for y:
{
// Get a write lock on our uniform buffer
let mut ub = self.uniform_buffer.write().unwrap();
// Set it to be a new matrix
(*ub)[0] = Mat4::from_translation(Vec3::new(-1.0, -1.0, 0.0))
* Mat4::from_nonuniform_scale(Vec3::new(2.0 / sz.x, 2.0 / sz.y, 1.0));
}
We'll go into more detail on transformation matrices after the break.
For now, remember that a matrix can represent a transformation (scale, translate, rotate), that multiplication "concatenates" transformations, and that the order of transformations is important.
Recall our normalized device coordinates "box" which goes from -1..1 in every dimension.
In this example, we're first moving the box over so that \(0,0\) is the top left corner (rather than \(1,-1\)), then scaling it so that 2 units of box space in x and become respectively sz.x or sz.y units of space.
Another way to read it is backwards: that we're defining a way of turning points from world space to NDC space, first by multiplying them by 2.0/size to normalize their positions, then by shifting them over to get them to the right place in NDC.
Next, we need to update the buffers used for data, creating them if necessary.
Updating bits and pieces of the GPU buffers doesn't make a lot of sense for us since the amount of data is fairly small (just locking the buffer for writes is expensive, and then the bookkeeping costs could outweigh the benefits), so no matter what we'll need to compute new vertex and possibly index data for every sprite.
Also, because we want adding and removing sprites to be cheap, we don't want to allocate exactly enough space for the sprites we have, but we want to allow for some overage.
That way we won't reallocate our buffers every single time a new sprite is added (or when a sprite is removed).
This is a lot of code, but don't be intimidated—read it carefully and see what iterator combinators are being used and why.
let count = posns.len(); // round up vert and idx to nearest power of two size // this won't give those buffers powers of two sizes but supports that power of two number of sprites let cap = count.next_power_of_two(); let vert_data = posns .iter() .zip(sizes.iter()) .zip(cels.iter()) .flat_map(|((pos, sz), cel)| { [ Vertex { position: [pos.x, pos.y], uv: [cel.x / tw, cel.y / th], }, Vertex { position: [pos.x, pos.y + sz.y], uv: [cel.x / tw, (cel.y + sz.y) / th], }, Vertex { position: [pos.x + sz.x, pos.y + sz.y], uv: [(cel.x + sz.x) / tw, (cel.y + sz.y) / th], }, Vertex { position: [pos.x + sz.x, pos.y], uv: [(cel.x + sz.x) / tw, cel.y / th], }, ] .into_iter() }) .chain(vec![Vertex{position:[0.0,0.0],uv:[0.0,0.0]};(cap - count)*4].into_iter()); let idx_data = (0..count) .flat_map(|which| { let base = (which * 4) as u16; [base, base + 1, base + 2, base + 2, base + 3, base] }) .chain(vec![0;(cap - count)*6].into_iter());
Now, there are two possibilities: either the SpriteData has set up its buffers or it hasn't.
I like if let for this, but don't take this code too seriously—if you want to support multiple different textures, you should probably be using a BTreeMap or something and then you can use the entry API to create new buffers if they don't exist yet.
In the end you'll have some code like this:
if let Some((old_count, verts, idxs, _pds)) = self.data.as_mut() { // Update the buffers if they exist already *old_count = count; { let mut verts_l = verts.write().unwrap(); if verts_l.len() < count*4 { // Oops, too small, recreate the buffer. // Note the manual use of drop to give up the lock on verts_l. drop(verts_l); *verts = CpuAccessibleBuffer::from_iter( device.clone(), BufferUsage::vertex_buffer(), false, // Just use our vert_data iterator! vert_data.collect::<Vec<_>>().into_iter(), ) .unwrap(); } else { // copy vert_data, it will fit. // if vert_data is shorter than verts_l, the remainder of // verts_l will be whatever it was before. for (vert, dat) in verts_l.iter_mut().zip(vert_data) { *vert = dat; } } } { // do the same thing for indices let mut idxs_l = idxs.write().unwrap(); if idxs_l.len() < count*6 { drop(idxs_l); *idxs = CpuAccessibleBuffer::from_iter( device, BufferUsage::vertex_buffer(), false, idx_data.collect::<Vec<_>>().into_iter(), ) .unwrap(); } else { for (idx, dat) in idxs_l.iter_mut().zip(idx_data) { *idx = dat; } } } } else { // If we're here, it means that we have never drawn any sprites (with this texture) before. // So just set up the buffers with the data we have... let verts = CpuAccessibleBuffer::from_iter( device.clone(), BufferUsage::vertex_buffer(), false, vert_data.collect::<Vec<_>>().into_iter(), ) .unwrap(); let idxs = CpuAccessibleBuffer::from_iter( device, BufferUsage::index_buffer(), false, idx_data.collect::<Vec<_>>().into_iter(), ) .unwrap(); // And set up our texture descriptor set let mut set_b = PersistentDescriptorSet::start( scheme .pipeline .layout() .descriptor_set_layouts() .get(1) .unwrap() .clone(), ); set_b .add_sampled_image( vulkano::image::view::ImageView::new(texi.clone()).unwrap(), scheme.sampler.clone(), ) .unwrap(); let pds = set_b.build().unwrap(); // This is what we've got! self.data = Some((count, verts, idxs, pds)); }
Now, a few hundred lines later, we're ready to draw sprites:
fn draw_sprites<P, L>(&self, ss: &SpriteScheme, builder: &mut AutoCommandBufferBuilder<P, L>) { builder // Bind the pipeline .bind_pipeline_graphics(ss.pipeline.clone()) // Bind the uniform descriptor .bind_descriptor_sets( vulkano::pipeline::PipelineBindPoint::Graphics, (*ss.pipeline).layout().clone(), 0, self.uniform_pds.clone(), ); // If using a BTreeMap, can iterate through them here if let Some((count, vs, is, pds)) = self.data.as_ref() { builder // bind vertex and index buffer .bind_vertex_buffers(0, vs.clone()) .bind_index_buffer(is.clone()) // bind texture and sampler .bind_descriptor_sets( vulkano::pipeline::PipelineBindPoint::Graphics, (*ss.pipeline).layout().clone(), 1, pds.clone(), ) // draw indexed. how many? count * 6! .draw_indexed(*count as u32 * 6, 1, 0, 0, 0) .unwrap(); } }
We finally made it!
fn main() { const W: f32 = 320.0; const H: f32 = 240.0; let mut engine = engine::Engine::new( Vec2::new(W, H), engine::WindowSettings { w: 1024, h: 768, ..Default::default() }, std::path::Path::new("content/king.png") ); use rand::prelude::*; { // Set up a bunch of sprites let mut rng = rand::thread_rng(); for _i in 0..256 { engine.add_sprite( Vec2::new(rng.gen::<f32>()*(W-12.0), rng.gen::<f32>()*(H-12.0)), Vec2::new(12.0, 16.0), Vec2::new(0.0, 16.0), ); } } engine.play(move |engine| { // Move 'em around a little every frame let (posns, _sizes, _cels) = engine.sprite_data_mut(); let mut rng = rand::thread_rng(); for s in posns.iter_mut() { let delta = Vec2::new(2.0 * rng.gen::<f32>() - 1.0, 2.0 * rng.gen::<f32>() - 1.0); s.x = (s.x + delta.x).clamp(0.0, W - 16.0); s.y = (s.y + delta.y).clamp(0.0, H - 16.0); } }); }

For comparison, see what changes between the single-texture and arbitrary-number-of-textutres versions of the project.
Next time, we'll talk about managing the large numbers of distinct assets (models, textures, etc) that 3D forces us to deal with, and the approaches taken going from sprite3d to sprites3d are illustrative there: TextureRef, in particular, shows the benefits of using opaque key types—although that one won't work great if textures can ever be unloaded, the general idea still stands!